
티스토리 뷰
편향(Bias) 의미
알고리즘을 만들 때 트레이닝 데이터 세트 중 특정 컬럼만 사용하는 것을 말한다.
예를 들어, 트레이닝 데이터 세트에 5개의 컬럼이 있을 때, 이중 1개만 사용한다.
실제로는 나머지 4개의 컬럼도 예측 결과에 영향을 주나, 알고리즘이 이를 간과하는 것이다.
그러므로, 편향은 예측 결과가 예상 결과와 다르게 한다.
편향이 높으면 데이터와 안맞는 과일반화, 과단순화, 과소적합 하는 특징이 있다.
분산(Variance) 의미
편향과 반대로 데이터의 모든 컬럼을 사용하는 것을 말한다.
예를 들면, 컬럼 중 필요 없는 노이즈도 사용한다.
분산이 높으면 트레이닝 데이터 세트에 과적합한다.
그러므로, 테스트 데이터 세트를 잘 예측할 수 없게 된다.
편향(Bias)과 분산(Variance)는 상충 관계
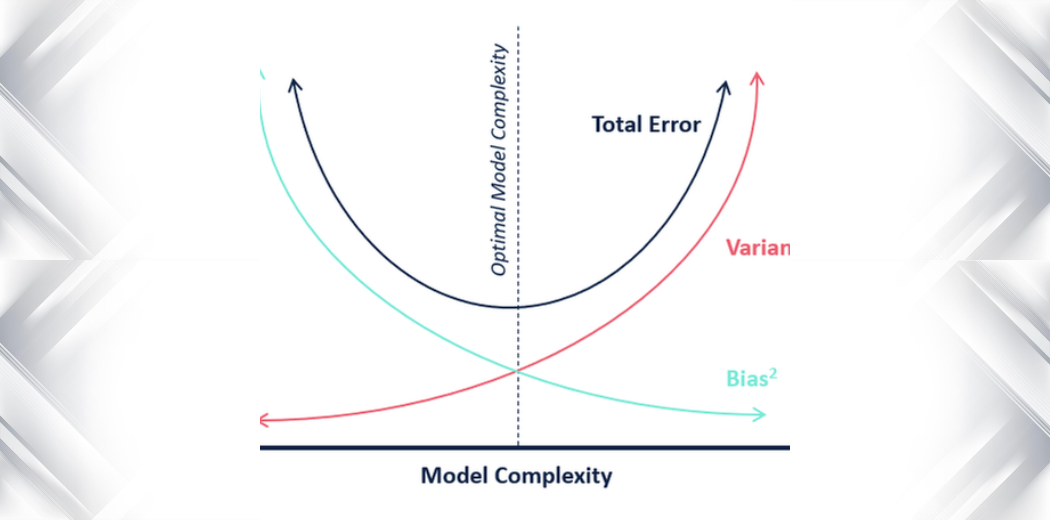
편향과 분산은 반비례 관계이다.
편향이 높은 모델은 분산이 낮다.
분산이 높은 모델은 편향이 낮다.
예를 들어, 머신러닝 알고리즘을 주어진 데이터 세트에 잘 맞게 조절하면, 편향을 낮추고 분산을 높인다.
이렇게 하면 모델은 데이터 세트에는 잘 맞고, 예측은 잘 못하게 된다.
참고
https://www.bmc.com/blogs/bias-variance-machine-learning/
https://www.analyticsvidhya.com/blog/2020/08/bias-and-variance-tradeoff-machine-learning/
'정보' 카테고리의 다른 글
| 자료구조 (0) | 2022.11.04 |
|---|---|
| 중심 극한 정리(Central limit Theorem)란? (0) | 2022.11.03 |
| 머신러닝 - 정규화란(Regularization)? (0) | 2022.11.03 |
| Searching 알고리즘이란? (0) | 2022.10.30 |
| Sorting 알고리즘이란? (0) | 2022.10.30 |
댓글
최근에 올라온 글
최근에 달린 댓글